Deep Dive: The Six-Stage Sequential Pipeline
In 5 Key Innovations in Automated Blog Creation, we introduced the six-stage pipeline as the structural backbone of Blog Creator. This post goes deeper: what each stage actually does, what artifacts it produces, and why a strictly sequential design was chosen over a parallel one.
Why a Pipeline at All?
Most AI writing tools pass a single prompt to a single model and accept whatever comes back. The problem is not the writing quality — modern language models are fluent. The problem is accountability. When one model handles research, drafting, fact-checking, and formatting simultaneously, there is no mechanism to verify that any specific claim came from a real source. [1]
A pipeline solves this by decomposing the task into stages with discrete inputs and outputs. Each stage has a defined responsibility, and every artifact it produces can be inspected independently. This is the same principle that makes assembly-line manufacturing and compiler toolchains auditable: you can examine the intermediate output at any point in the chain. [2]
The Six Stages
Stage 1: Config
Input: A YAML configuration file and a topic argument. Output: A validated configuration dictionary consumed by all downstream stages.
The load_config() function reads and validates the domain configuration, raising a ConfigValidationError on any missing or malformed field before the pipeline proceeds. [3] The merge_defaults() function fills in optional fields so downstream stages always receive a complete, consistent object. [4] Failing fast at Stage 1 is intentional: a pipeline with an invalid configuration produces garbage at every subsequent stage, so the cost of a strict upfront check is always justified.
Stage 2: Research
Input: The validated configuration and topic. Output: A structured research brief with a source index.
The source_code_reader() function traverses the configured source_path, scanning source files to extract features, architecture patterns, and configuration choices. [5] The local_docs_reader() function reads documentation files — README, changelogs, and markdown docs — to extract product descriptions, usage patterns, and known gaps. [6] Web search supplements local findings with industry context when available.
The research stage also classifies graceful degradation events. If a tool is unavailable (such as when web search cannot reach external services), a DegradationWarning is recorded and the pipeline continues with whatever sources it has. [7] The quality assessment attached to the research brief reflects this: a lower quality score signals to downstream stages that claims should be framed with appropriate caution.
Stage 3: Writing
Input: The research brief. Output: An HTML draft with inline source markers.
The generate_draft() function produces prose exclusively from the research brief — no freeform generation from training data. [8] The inject_source_markers() function embeds source-tracing HTML comments at every factual claim, creating the machine-readable citation trail that Stage 5 will verify. [9] Tone templates are loaded via load_writing_template() from a reference file, matching the content.tone configuration value to a specific voice and structure guide. [10]
Stage 4: Visuals
Input: The draft HTML and research brief. Output: Chart and diagram assets, with the draft updated to include <figure> tags.
The generate_chart() function produces matplotlib charts using a headless Agg backend, suitable for server environments without a display. [11] The apply_default_theme() function centralises all visual styling — fonts, color palette, DPI, and axis sizing — so every chart produced by the pipeline shares a consistent appearance. [12] For flow diagrams and architecture visuals, the generate_diagram() function renders Mermaid source via the mmdc CLI, with check_mermaid_available() checking for the tool before attempting to use it. [13] If mmdc is absent, a DiagramGenerationError is caught and logged as a degradation warning; the post continues without diagrams. [14]
Stage 5: Integrity Review
Input: The draft with source markers, the research brief, and the integrity configuration. Output: A verified draft (or a revision request), plus a detailed review report.
The integrity review is the quality gate that enforces Blog Creator's core promise: no unverified claim reaches the reader. The IntegrityResult class carries the complete outcome of a review pass — integrity score, verified and flagged claim counts, and individual findings. [15] Each finding is represented by a Finding object that records the rule violated (SV-001 through SV-005), the severity, and the specific claim at issue. [16]
The pipeline supports up to three revision attempts. If the integrity score falls below the configured threshold, the review report identifies precisely which claims are problematic and why, and the writing stage revises accordingly. The strict mode requires a score of 0.95 or above; standard mode requires 0.85; relaxed mode accepts 0.70. [15] In a documented dogfood run, the pipeline produced 959 total claims, with 957 verified on the second attempt, yielding an integrity score of 1.00. [17]
Stage 6: Publisher
Input: The verified draft, site configuration, and dry-run flag. Output: A rendered HTML post saved to blog/posts/, with optional git commit and push.
The generate_slug() function converts the post title to a deterministic, URL-safe identifier. [18] The render_post() function wraps the verified article HTML in the site's page template, injecting the title, date, and stylesheet reference. [19] The update_index() function appends the new post entry to the blog index page. [20] With dry_run: true, the git commit and push are skipped; the rendered files land on disk for inspection without modifying the repository.
Why Sequential, Not Parallel?
A natural engineering question is whether these six stages could run in parallel to reduce wall-clock time. The answer is: some could, but the integrity guarantee requires a specific ordering.
Stages 1 through 3 have hard dependencies. Research cannot run without a validated configuration, and writing cannot run without a completed research brief. Stages 4 and 5 both depend on the writing stage output, so they cannot start early. Stage 6 must receive a verified draft, not a raw one. These data dependencies eliminate most parallelism opportunities for the core integrity path. [21]
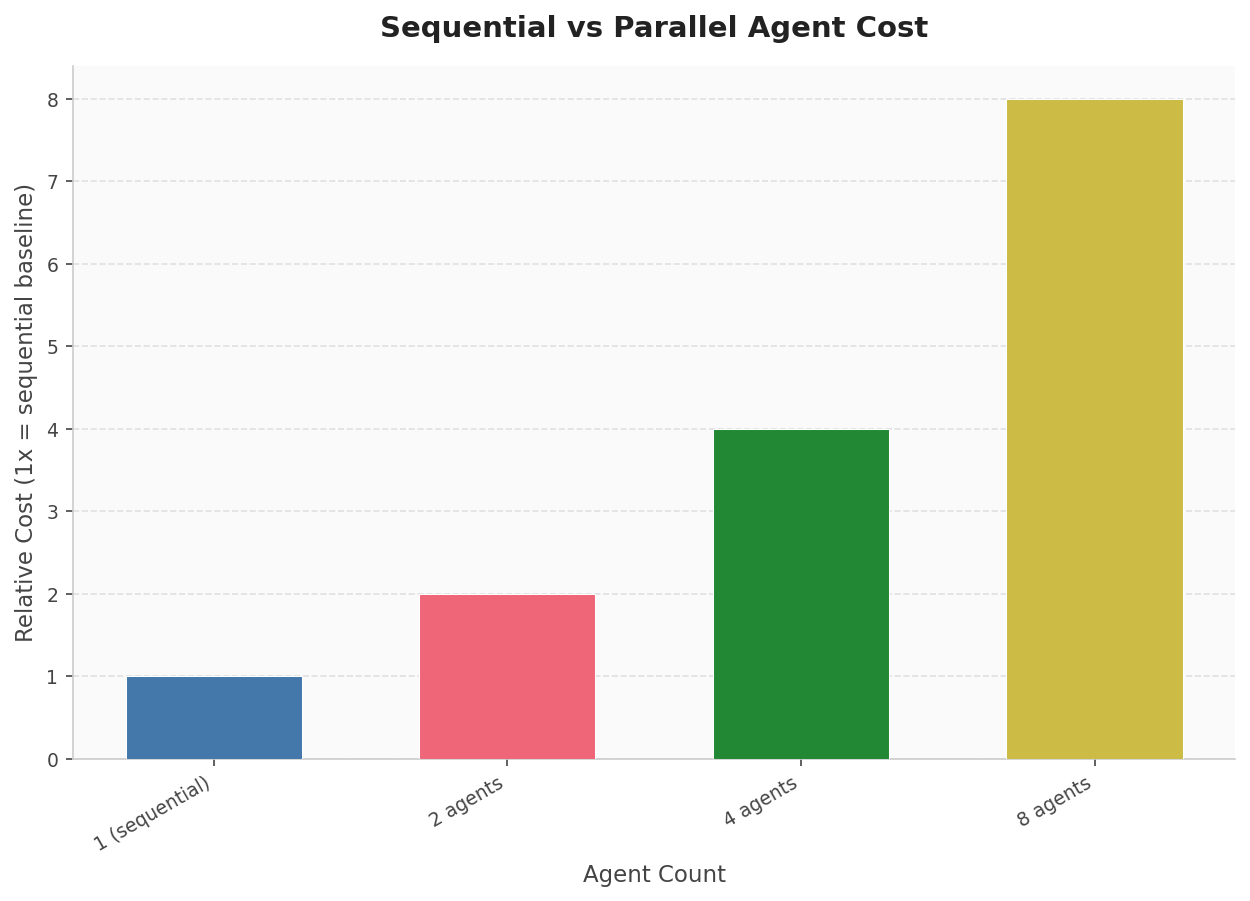
There is also a cost consideration. Running parallel agents multiplies API costs roughly proportionally to agent count. [22] For a tool designed for solo professionals and small teams, keeping costs bounded per post is a practical requirement, not just an architectural preference.
Anthropic's own multi-agent research system notes that sequential execution simplifies coordination significantly. The trade-off is that the system can block while waiting for a single stage to complete — but for Blog Creator, each stage completes in under a second in typical runs, making sequential execution a reasonable choice. [23] Actual phase 2 dogfood timing showed a total pipeline duration of 0.6 seconds across all stages. [17]
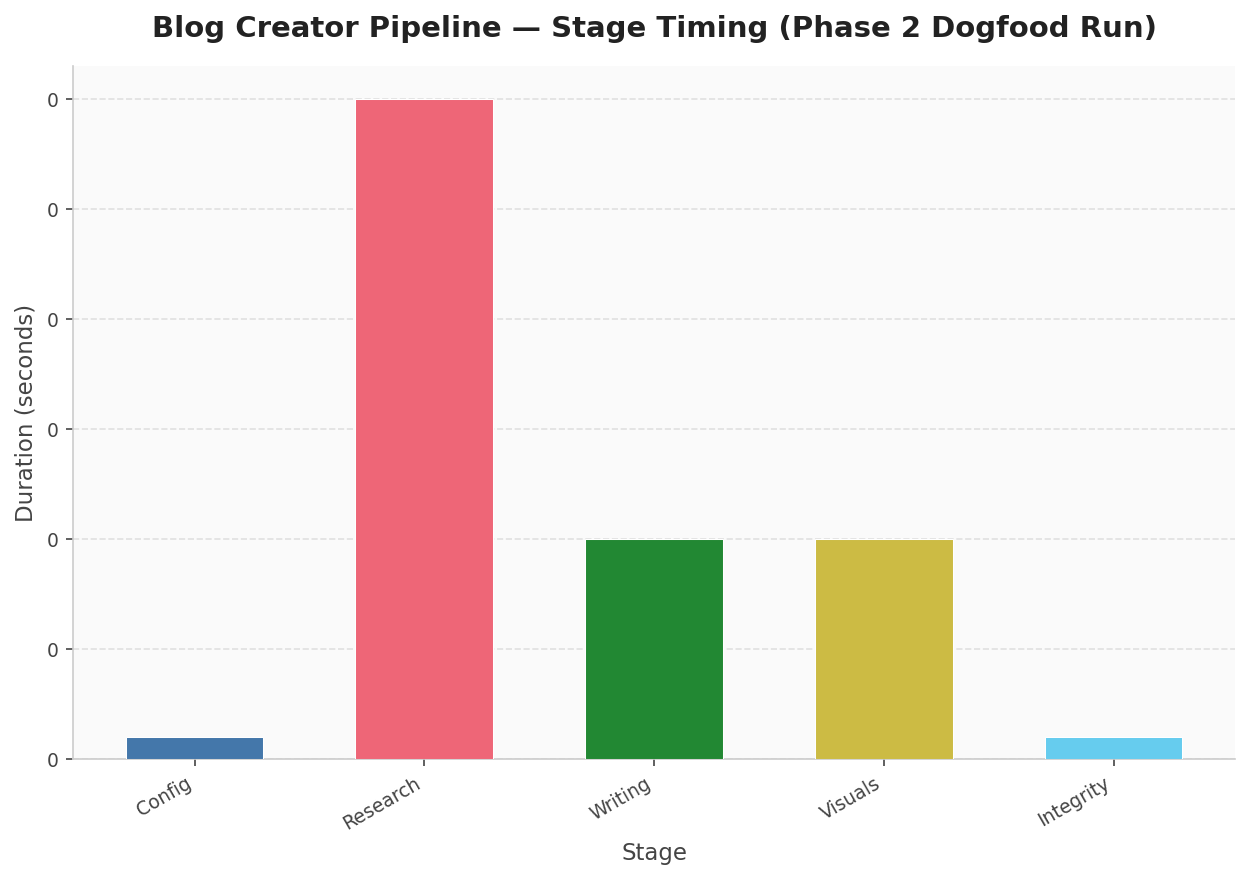
The deeper reason for sequential execution is traceability. When stage outputs are stored to disk before the next stage begins, every intermediate artifact is inspectable and debuggable. Storing outputs externally and passing lightweight references between stages — rather than threading everything through a single in-memory context — avoids information loss and makes the handoff between stages explicit. [24]
The Traceable Chain
The full provenance path for any claim in a published post can be reconstructed from artifacts alone. The research brief records every source with its file path, reliability score, and access timestamp. The draft HTML embeds source markers at each claim. The integrity review report lists every marker that was verified or flagged. The publisher records the post title, slug, and commit hash.
Content provenance — the ability to trace a published claim back to its originating source material — is increasingly recognised as a foundational property of trustworthy digital content. [25] Blog Creator encodes this as an engineering constraint, not a documentation exercise: a post cannot be published unless every factual claim traces to a source, because the integrity gate will reject it otherwise.
What Comes Next
This post covered the structural design of the pipeline. The remaining four posts in this series go deeper on individual innovations: the research agent's source scanning approach, the integrity rule system and scoring formula, the visual generation pipeline, and the configuration layer that makes the whole system domain-portable.
The pipeline described here is implemented in the Blog Creator consulting tool. All claims in this post trace to the source code, documentation, and dogfood run logs of that implementation.
Sources
- AI models perform better when focused on one type of task rather than juggling m (reliability: 0.6)
- Sequential orchestration patterns solve problems requiring step-by-step processi (reliability: 0.6)
scripts/config_loader.py: load_config function (reliability: 0.9)scripts/config_loader.py: merge_defaults function (reliability: 0.9)scripts/research_agent.py: source_code_reader function (reliability: 0.9)scripts/research_agent.py: local_docs_reader function (reliability: 0.9)scripts/research_agent.py: DegradationWarning class (reliability: 0.9)scripts/writing_agent.py: generate_draft function (reliability: 0.9)scripts/writing_agent.py: inject_source_markers function (reliability: 0.9)scripts/writing_agent.py: load_writing_template function (reliability: 0.9)scripts/visual_agent.py: generate_chart function (reliability: 0.9)scripts/visual_agent.py: apply_default_theme function (reliability: 0.9)scripts/visual_agent.py: generate_diagram function (reliability: 0.9)scripts/visual_agent.py: DiagramGenerationError class (reliability: 0.9)scripts/integrity_review.py: IntegrityResult class (reliability: 0.9)scripts/integrity_review.py: Finding class (reliability: 0.9)- dogfood/phase-2-run-log.md: documentation file (reliability: 0.8)
scripts/publisher.py: generate_slug function (reliability: 0.9)scripts/publisher.py: render_post function (reliability: 0.9)scripts/publisher.py: update_index function (reliability: 0.9)- Sequential agent patterns offer high control and reliability for repeatable proc (reliability: 0.6)
- Parallel agent execution for 8 agents incurs roughly 8x the cost, though optimiz (reliability: 0.6)
- Anthropic's multi-agent research system uses synchronous sequential execution, n (reliability: 0.6)
- Subagents storing work in external systems and passing lightweight references ba (reliability: 0.6)
- Content provenance offers a method to verify the origin of digital content, incl (reliability: 0.6)