5 Key Innovations in Automated Blog Creation: How Source-Verified Content Changes Everything
Most AI writing tools generate fluent text with no guarantee that any of it is true.[1] Blog Creator takes a different approach: a six-stage pipeline where every factual claim traces back to verified source code, documentation, or research.[2] Here are the five engineering decisions that make that possible — and why they matter for anyone publishing technical content.
The Problem: Fluency Without Accountability
The Merriam-Webster Word of the Year for 2025 was "slop" — a term for the flood of low-quality, generic AI-generated content saturating the web.[1] Most AI blog generators produce text from training data alone, with no mechanism to verify that what they write actually reflects reality.[3]
Blog Creator was built to solve this specific problem: generate original, compelling blog content where every factual claim is traceable to its source.[4] The system achieves this through five key innovations.
Innovation 1: The Six-Stage Sequential Pipeline
Rather than asking a single LLM to "write a blog post," Blog Creator decomposes content creation into six discrete stages: Config, Research, Writing, Visuals, Integrity Review, and Publisher.[5] Each stage produces artifacts consumed by the next, creating a traceable chain from raw source material to published post.
This architecture mirrors how multi-agent content pipelines in production achieve higher quality than single-pass generation.[6] The key difference is that Blog Creator enforces strict stage boundaries — the writing stage cannot access raw source code, only the structured research brief.[7] This prevents the LLM from hallucinating details it "saw" in training data rather than using verified findings.
Each stage is instrumented with timing metrics, enabling performance analysis across the full pipeline.[8] When something goes wrong, you know exactly which stage failed and why — no black-box debugging.
Innovation 2: Source-Level Research with Citation Traceability
The research stage does not rely on the LLM's training data. Instead, it runs deterministic source scanners that extract findings directly from product source code and documentation.[7] The source_code_reader() function performs file system traversal and content analysis to identify features, architecture patterns, and configuration choices from actual code repositories.[7]
The local_docs_reader() complements this by parsing README files, documentation directories, changelogs, and other markdown files to extract product descriptions, features, and usage instructions.[9] Every extracted finding carries a source reference — the file path, the specific detail, and a reliability score.
Web research adds industry context through targeted searches, but these sources are assigned a lower reliability score of 0.6 by default, reflecting the reduced verifiability of web content compared to source code you control.[10] All findings converge into a unified source index that the integrity review stage later uses to validate every claim in the finished post.
This approach aligns with emerging AI governance frameworks that emphasize source traceability — designing AI systems so that users and auditors can trace claims back to their origins.[11]
Innovation 3: Integrity Review with Automated Revision
The integrity review stage is the system's quality gate. It extracts every source marker from the draft HTML and cross-references each one against the research brief's source index.[12] This is not a stylistic check — it is a structural verification that every factual claim has a documented origin.
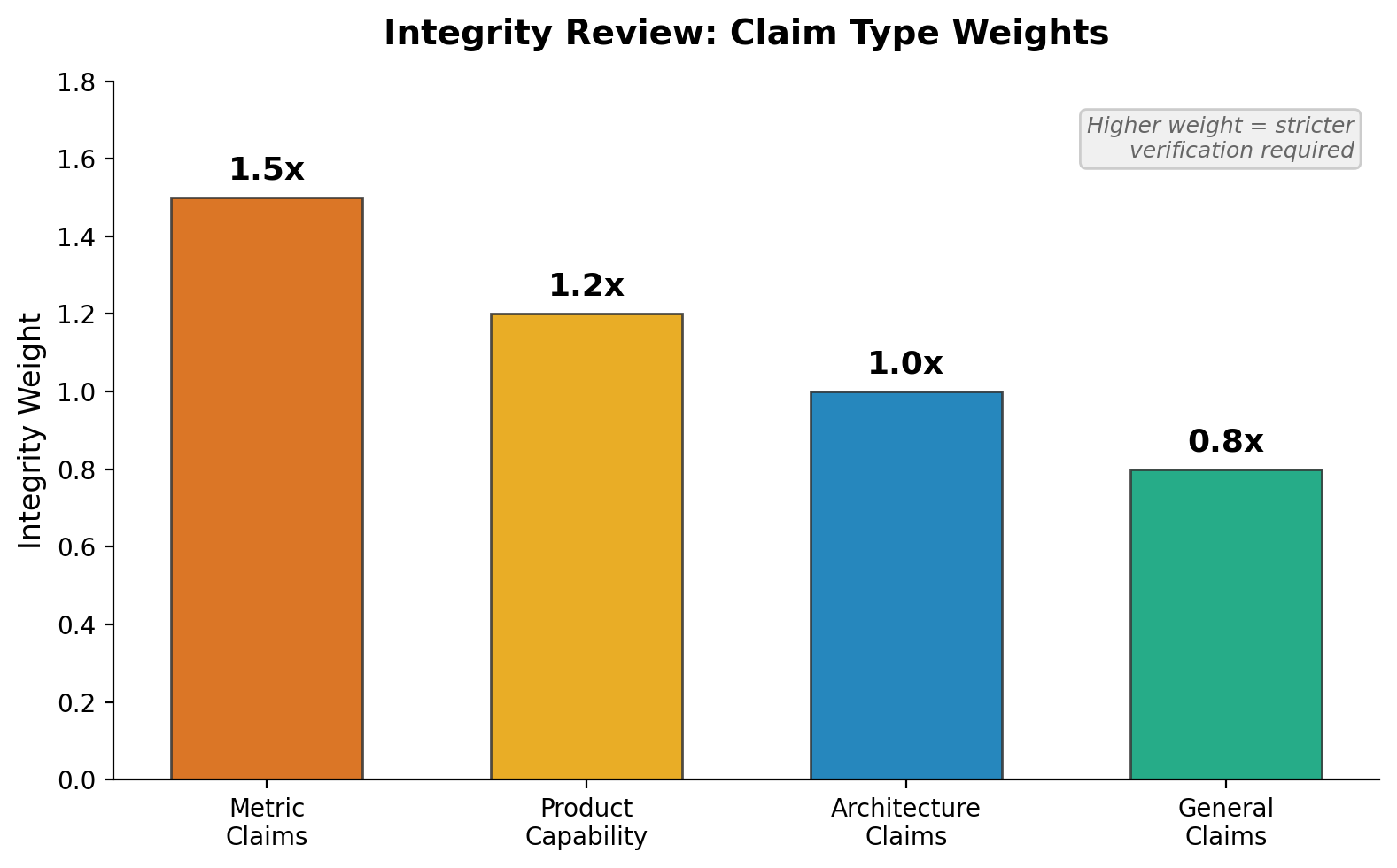
The review produces an integrity score using weighted claim types. Metrics carry a weight of 1.5, product capability claims 1.2, architecture claims 1.0, and general claims 0.8.[4] This weighting reflects a practical insight: a fabricated performance number does more damage to credibility than an unsourced general observation.
Four categories of findings are flagged: unsourced claims (SV-001), broken references that do not match any source index entry (SV-002), invalid source types (SV-003), and low-reliability citations (SV-004).[2] The strictness threshold is configurable — strict requires a score of 0.95 or higher, standard requires 0.85, and relaxed accepts 0.70.[13]
When the review fails, the system enters an automated revision loop, giving the writing agent up to three attempts to fix flagged issues.[2] It corrects broken references, adds missing citations, or softens unsourced claims. This self-healing behavior reduces the manual intervention required to produce verified content.
Innovation 4: Domain Configuration as a Single Source of Truth
Blog Creator is not a generic tool — it adapts to the creator's identity, products, and editorial standards through a single YAML configuration file.[5] The configuration covers seven distinct concerns: brand identity, product catalog with source paths, content tone and audience, integrity strictness, asset generation settings, per-agent model selection, and publishing targets.[14]
This is more than a settings file. The product entries include source_path and docs_path fields that point to actual repositories on disk.[15] The config loader validates that these paths exist at startup — a missing source directory is caught before the pipeline begins, not after ten minutes of LLM calls.[14]
Default values are merged for optional fields, so a minimal config with just brand name, domain, and one product entry is sufficient to run the pipeline.[16] Per-agent model selection lets you assign different Claude models to different stages — for example, using Sonnet for research and writing but Opus for the integrity review where precision matters most.[13]
Innovation 5: Data-Driven Visuals from Real Research
Most AI content tools either skip visuals entirely or generate decorative images. Blog Creator takes a different approach: it creates charts and diagrams from the actual research data gathered in Stage 2.[17] Matplotlib generates data-driven charts — module sizes, feature counts, comparison metrics — rendered as professional PNGs with colorblind-friendly palettes at 150+ DPI.[17]
Architecture diagrams are rendered via Mermaid when available, with graceful degradation to chart-only output if mmdc is not installed.[13] This graceful degradation pattern runs throughout the pipeline — missing optional tools reduce output quality but never crash the process.[8]
Every visual is embedded in the draft using semantic <figure> tags with descriptive alt text and captions.[17] The visuals are not decoration — they are evidence, derived from the same verified sources as the text.
What This Means for Technical Content
These five innovations address the core problem with AI-generated content: the gap between fluency and accuracy.[1] Rather than optimizing for speed and volume — the approach that produced the "slop" problem — Blog Creator optimizes for verifiability.[4] Every post it produces comes with a built-in audit trail: from source code to research brief, from research brief to cited claim, from cited claim to numbered footnote in the published article.
In future posts in this series, we will take a deeper dive into each of these five innovations individually, examining the engineering trade-offs and lessons learned during development.
Sources
- Miriam Webster Word of the Year 2025 was 'slop' referring to glut of low-quality (reliability: 0.6)
scripts/integrity_review.py: Finding class (reliability: 0.9)- Most AI blog platforms generate content without source verification, relying sol (reliability: 0.6)
scripts/integrity_review.py: IntegrityResult class (reliability: 0.9)scripts/config_loader.py: load_config function (reliability: 0.9)- Multi-agent content pipelines where research informs writing and writing feeds q (reliability: 0.6)
scripts/research_agent.py: source_code_reader function (reliability: 0.9)scripts/research_agent.py: DegradationWarning class (reliability: 0.9)scripts/research_agent.py: local_docs_reader function (reliability: 0.9)scripts/research_agent.py: web_search_researcher function (reliability: 0.9)- Source traceability in AI governance means enabling users to trace claims to the (reliability: 0.6)
scripts/integrity_review.py: _ExtractedMarker class (reliability: 0.9)- blog-creator-definition.md: documentation file (reliability: 0.8)
scripts/config_loader.py: validate_config function (reliability: 0.9)tests/test_config_loader.py: test_nonexistent_source_path function (reliability: 0.9)scripts/config_loader.py: merge_defaults function (reliability: 0.9)- blog-creator-description.md: documentation file (reliability: 0.8)