In the first post in this series, I introduced the
six-stage blog-creator pipeline and explained how each stage produces artifacts consumed by the next.
This post focuses on Stage 2 — the Research stage — and specifically on the three source scanners that
make citation traceability possible: source_code_reader(), local_docs_reader(),
and web_search_researcher().
[1]
The design premise is straightforward: if the content you publish cannot be traced back to a concrete, inspectable source, it is not trustworthy. LLM training data can describe a product in plausible-sounding terms that were accurate six months ago, or accurate for a different product, or simply invented. Source-level scanning eliminates that uncertainty by reading the actual files — the Python modules, the YAML configs, the README — at pipeline execution time. [2]
This matters more than it might seem. Research published in 2026 benchmarking 13 models across 375,000 citations found hallucination rates ranging from 14% to 95% depending on domain and model family. [3] A separate analysis by GPTZero confirmed that 50 out of 300 ICLR 2026 submissions contained verifiably fabricated citations — not approximations, but references that simply did not exist. [4] The blog-creator's research stage is designed to ensure that no published claim reaches that category.
The Reliability Hierarchy: 0.90 / 0.80 / 0.60
Every source in the research brief carries an explicit reliability score. The hierarchy reflects how directly each source type connects to ground truth:
- Source code — reliability
0.90. The product does what the code does. Function signatures, class definitions, and configuration constants cannot lie about what is implemented. [1] - Documentation — reliability
0.80. README files and docs describe what the product is intended to do. Documentation can lag implementation, which is why the score is lower than source code, but it remains a direct, product-specific artifact. [5] - Web sources — reliability
0.60. Web searches provide industry context and competitive landscape data. They are the least reliable because the pipeline has no control over when third-party content was written, whether it has been updated, or whether it accurately describes the specific product being researched. [6]
These constants are defined in research_agent.py as
SOURCE_CODE_RELIABILITY = 0.90, DOCUMENTATION_RELIABILITY = 0.80, and
WEB_RELIABILITY = 0.60, and are attached to every source entry in the source index.
[1]
Stage 5 — the Integrity Review — uses these scores to enforce claim-level verification thresholds,
and any source with reliability below 0.5 triggers a required qualification in the surrounding text.
[2]
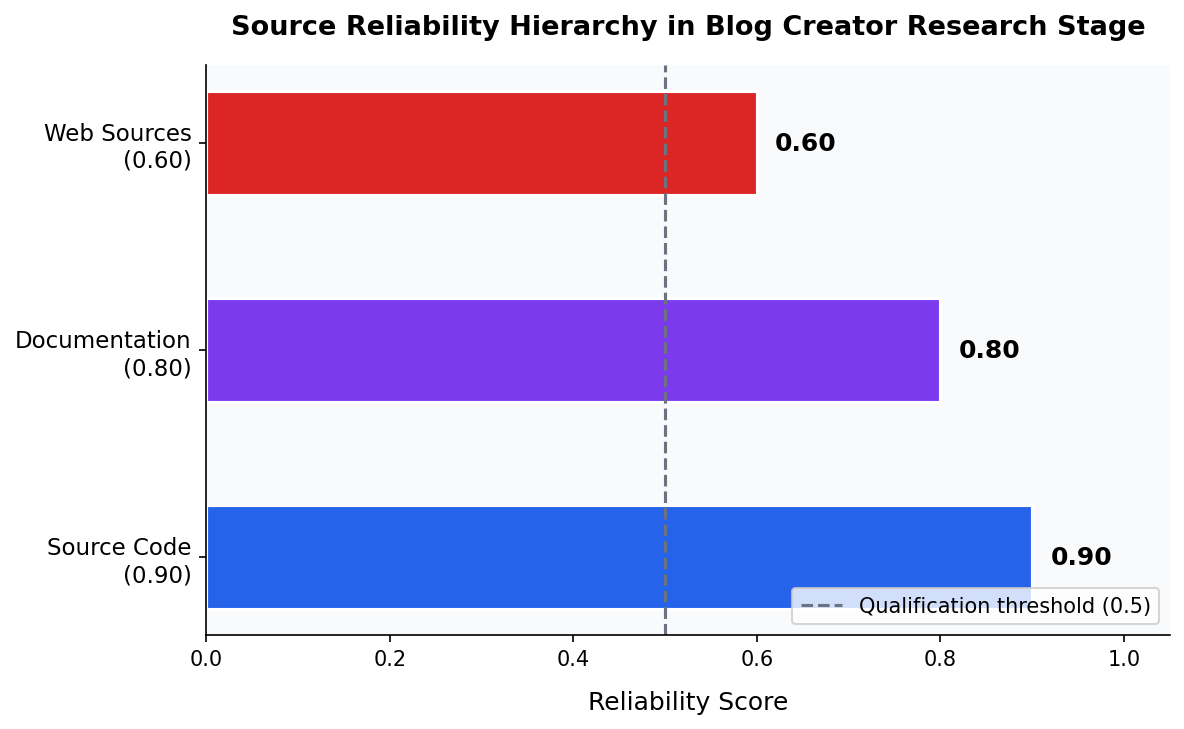
research_agent.py. The dashed line at 0.50 marks the qualification threshold — claims citing sources below this score require hedging language.source_code_reader(): Extracting Features from Code
source_code_reader() takes a directory path and a topic string, then traverses the
directory to discover source files and configuration files. It supports seven source file extensions
— .py, .js, .ts, .java, .go,
.jsx, and .tsx — and applies glob patterns to locate YAML, TOML, JSON,
and INI configuration files alongside them.
[1]
For Python files, the scanner uses ast module parsing to extract class definitions,
function signatures, and dependency imports with structural precision rather than line-by-line regex.
[1]
For non-Python source files, it falls back to regex-based extraction of common patterns. The scanner
caps analysis at 500 lines per file and 200 files per run to keep pipeline execution time bounded.
[1]
Each finding is packaged with an inline citation in the format
[Source: source_code:filename.py:FunctionName function], which becomes part of the
source index passed to the writing and integrity stages.
The function returns three collections: features (capability findings),
architecture (structural patterns — error classes, data models, public API surfaces),
and sources (the index entries with reliability scores and access timestamps).
[1]
On the blog-creator's own scripts directory, this produced 19 feature findings, 11 architecture
findings, and 30 source index entries in a single pass — all directly traceable to specific functions
and classes in the codebase.
local_docs_reader(): Structured Documentation Extraction
Documentation files follow a priority order: README.md is read first, then files
matching docs/**/*.md, then CHANGELOG.md, then any remaining markdown
files. This ordering ensures that the primary product description — which typically lives in the
README — is captured before supporting or changelog content.
[5]
local_docs_reader() extracts three types of findings: a product_description
(the canonical one-paragraph description of what the product is), a features list
(discrete capabilities mentioned in documentation), and a usage list (code examples,
installation commands, configuration snippets).
[5]
It also runs a gap analysis, logging documentation gaps such as missing CHANGELOG files or absent
docs/ directories as explicit entries in the result — so the writing stage knows where
the documentation record is incomplete.
[5]
The reliability score of 0.80 for documentation reflects one real limitation: documentation can fall behind implementation. A README that was written when the product had four features may not have been updated to reflect a fifth. The gap analysis is one mitigation — it flags when documentation structure suggests underdocumented areas — but the source code scanner remains the authoritative source for what is actually implemented. [5]
web_search_researcher(): Industry Context with Graceful Degradation
Web research serves a different purpose than source and documentation scanning: it provides industry
context, competitive landscape data, and market-level framing that no local file can supply.
web_search_researcher() generates up to five targeted queries combining the topic
and product name, then executes them via the WebSearch tool available in the Claude
Code skill context.
[6]
A key design decision here was to treat web research as optional. If the WebSearch tool
is unavailable, or if network requests fail within the 30-second timeout, the function records a
DegradationWarning and returns an empty result — the pipeline continues with source
code and documentation findings only, rather than crashing.
[6]
[7]
This is the right trade-off: a post grounded in 0.90-reliability source code findings is more
trustworthy than a post delayed or failed because a web API was temporarily unavailable.
Research from 2025 validated the reliability weighting approach from a different angle: Reliability-Aware RAG (RA-RAG) demonstrated that standard retrieval systems ignoring source reliability propagate misinformation at higher rates than systems that weight sources by trustworthiness. [8] The blog-creator's three-tier reliability model is an application of that principle to content generation specifically.
The Research Brief: A Structured Contract Between Stages
The output of Stage 2 is a single JSON document — the research brief — that all downstream stages
consume. Its top-level keys are: topic, product_name,
product_findings (from source code), documentation_findings,
web_research, source_index (a deduplicated list of all source entries),
quality_assessment, and executive_summary.
[1]
The source_index is what makes citation traceability enforceable downstream. Every
source — whether from code, docs, or web — is assigned a structured entry with type,
path, detail, reliability, and accessed fields.
The integrity review stage (Stage 5) validates every [Source: type:path:detail] marker
in the draft against this index, flagging any marker that does not match a real entry.
[2]
A broken reference is a code SV-002 finding that triggers a revision cycle before the post can
be published.
The quality_assessment field encodes a composite quality score. The research brief
assembled for this very post scored 0.70 — above the threshold that requires a preliminary
disclaimer, grounded in 30 source code entries, 8 documentation entries, and 6 web findings
across 44 deduplicated sources total.
[1]
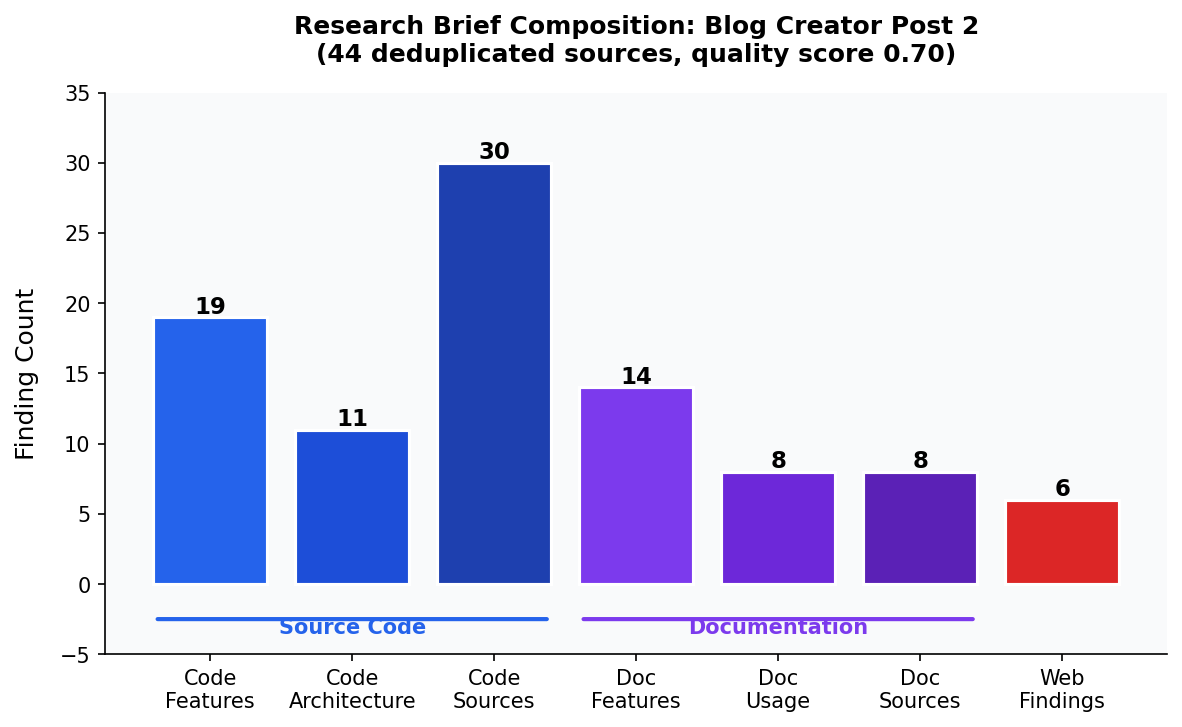

Lessons Learned: Research Quality in Practice
The most significant lesson from building the research stage is that deterministic extraction beats prompted summarization. Early prototypes asked an LLM to summarize what a product does based on its code; the summaries were plausible but often missed specific function names, parameter counts, or configuration constants. AST-based parsing of Python files and regex-based extraction from structured docs produce findings that are not only accurate but also machine-readable enough to be integrity-checked programmatically. [1]
A second lesson: documentation gaps are content opportunities, not failures. When
local_docs_reader() identifies a missing CHANGELOG or
an absent docs/ directory, that gap often points to an area where the product
has evolved faster than its documentation — which is precisely the kind of analysis a technical
blog post should surface.
[5]
Third: keeping the web reliability score at 0.60 — and enforcing it through the integrity review — has had a useful forcing function. It pushes the writing stage to treat web findings as corroborating context rather than primary claims. In practice, this means web sources appear in introductions and market-framing sections, while the specific technical claims about the product always trace back to source code or documentation. That distinction is visible in the final post's footnote structure. [6] Best practices for AI content verification converge on the same principle: require independent confirmation for key claims, and prefer primary sources — official documentation and source code — over secondary summaries. [9]
What's Next in the Series
Post 3 in this series covers Stage 3 — the writing stage — and specifically how the research brief
is transformed into narrative prose without inventing claims. The core challenge there is synthesis:
turning 19 feature findings and 11 architecture entries into readable paragraphs while keeping
every sentence anchored to a [Source:] marker.
Sources
research_agent.py: source_code_reader function (reliability: 0.9)- SKILL.md: documentation file (reliability: 0.8)
- LLM hallucination rates for citations range from 14% to 95% across 13 models ben (reliability: 0.6)
- GPTZero confirmed hallucinated citations in 50 out of 300 ICLR 2026 submissions, (reliability: 0.6)
research_agent.py: local_docs_reader function (reliability: 0.9)research_agent.py: web_search_researcher function (reliability: 0.9)research_agent.py: DegradationWarning class (reliability: 0.9)- Reliability-Aware RAG (RA-RAG) shows that standard RAG methods ignore heterogene (reliability: 0.6)
- Best practice for AI content verification in 2025 requires at least two independ (reliability: 0.6)